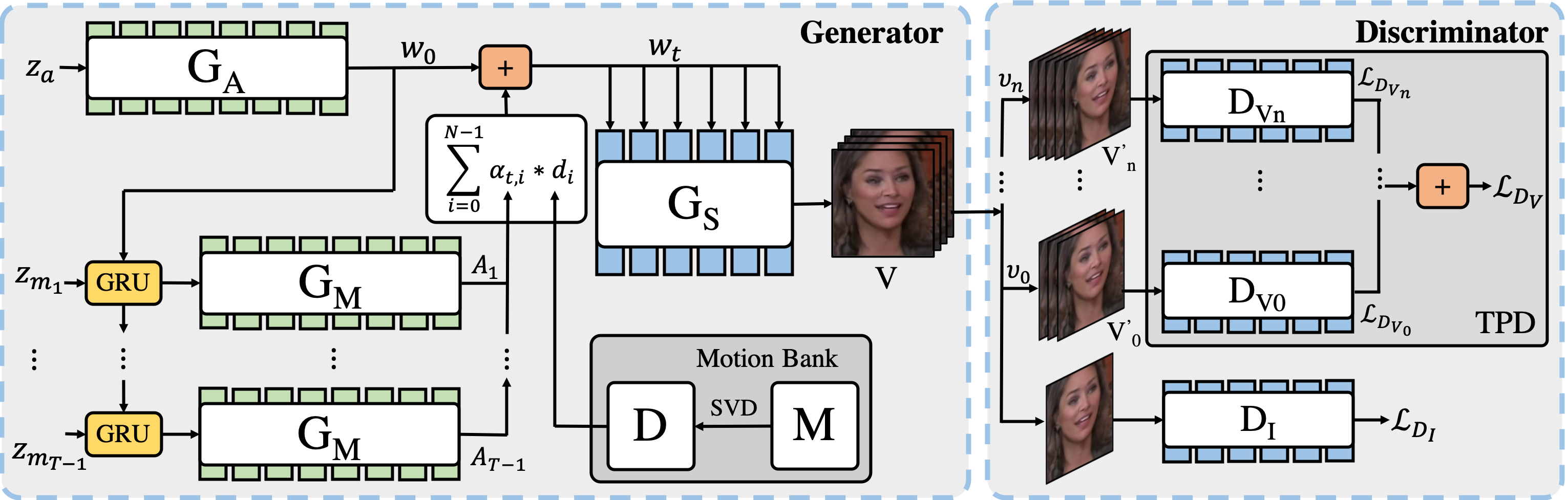
In this work, we introduce an unconditional video generative model, InMoDeGAN, targeted to (a) generate high quality videos, as well as to (b) allow for interpretation of the latent space. For the latter, we place emphasis on interpreting and manipulating motion. Towards this, we decompose motion into semantic sub-spaces, which allow for control of generated samples. We design the architecture of InMoDeGAN-generator in accordance to proposed Linear Motion Decomposition, which carries the assumption that motion can be represented by a dictionary, with related vectors forming an orthogonal basis in the latent space. Each vector in the basis represents a semantic sub-space. In addition, a Temporal Pyramid Discriminator analyzes videos at different temporal resolutions. Extensive quantitative and qualitative analysis shows that our model systematically and significantly outperforms state-of-the-art methods on the VoxCeleb2-mini and BAIR-robot datasets w.r.t. video quality related to (a). Towards (b) we present experimental results, confirming that decomposed sub-spaces are interpretable and moreover, generated motion is controllable.
1. Random Generation
We randomly sample different appearance noises za and motion noise sequences {zm0,zm1,...,zmT-1} on VoxCeleb2-mini in two resolutions (128x128, 64x64) and BAIR-robot.
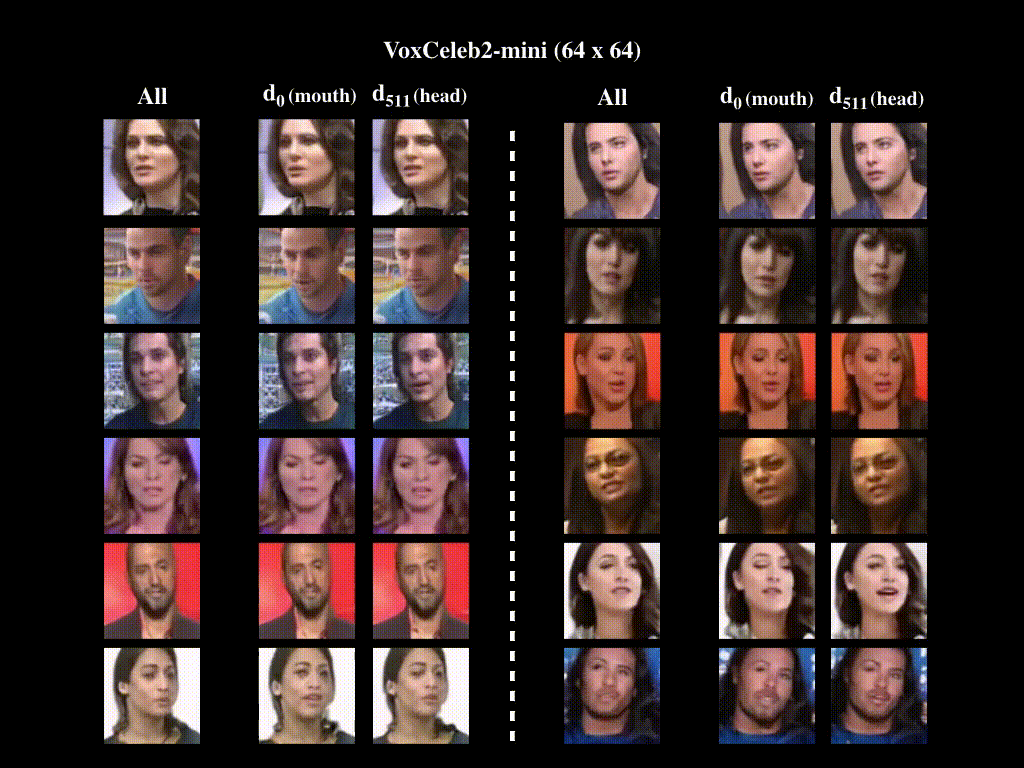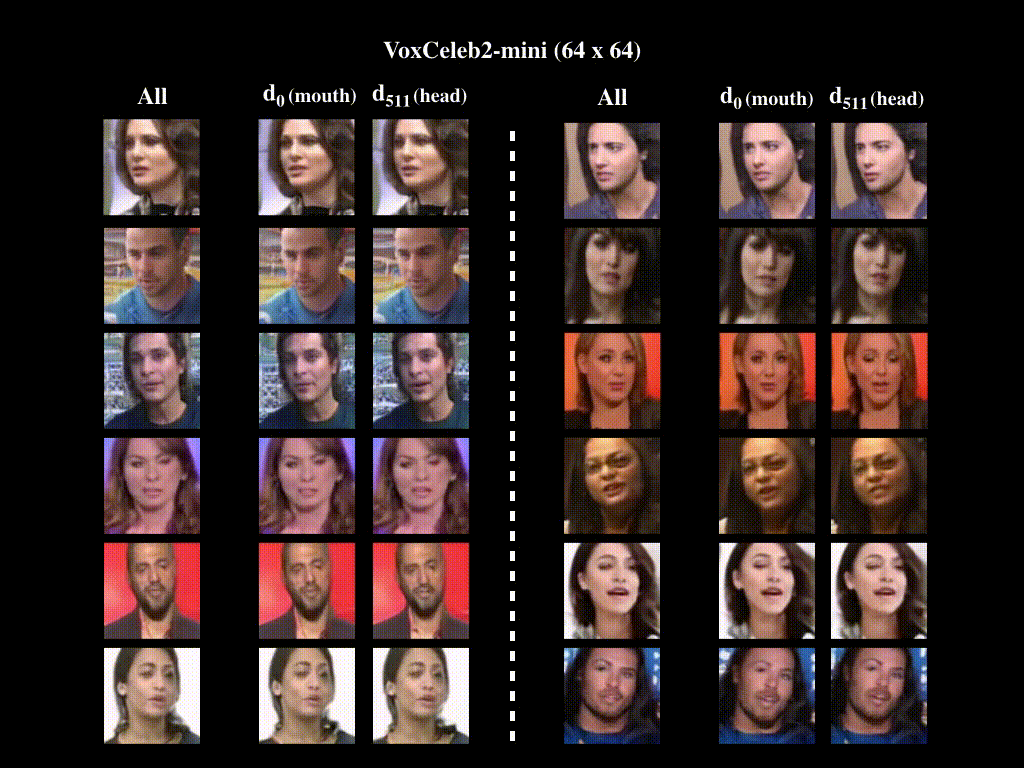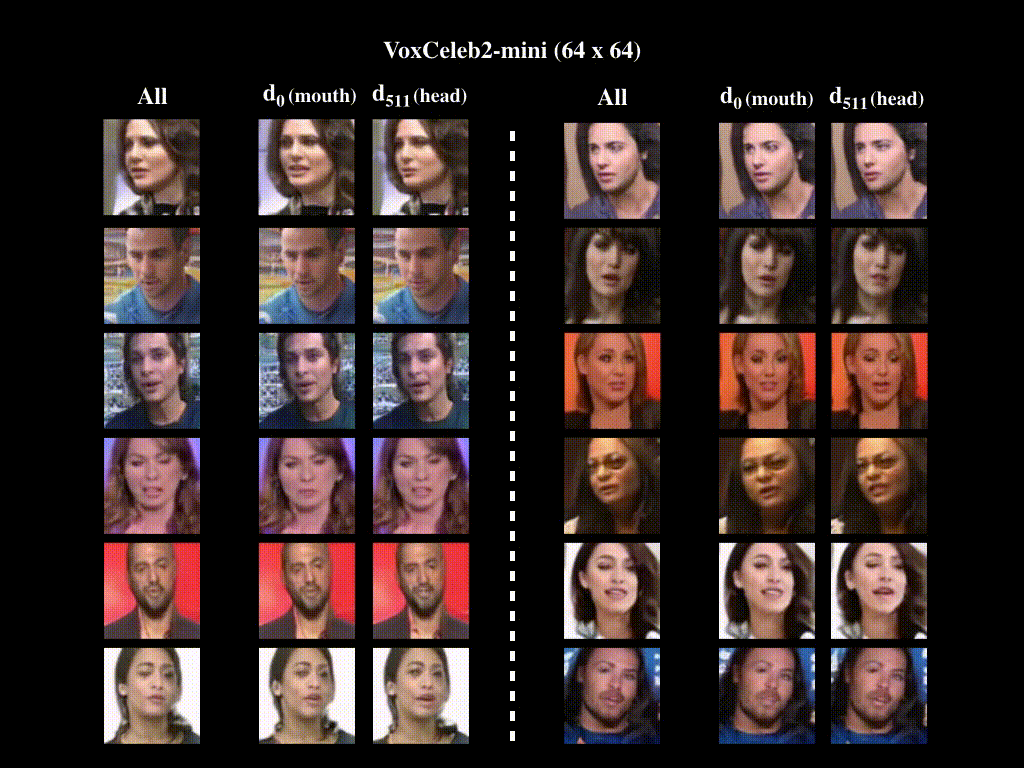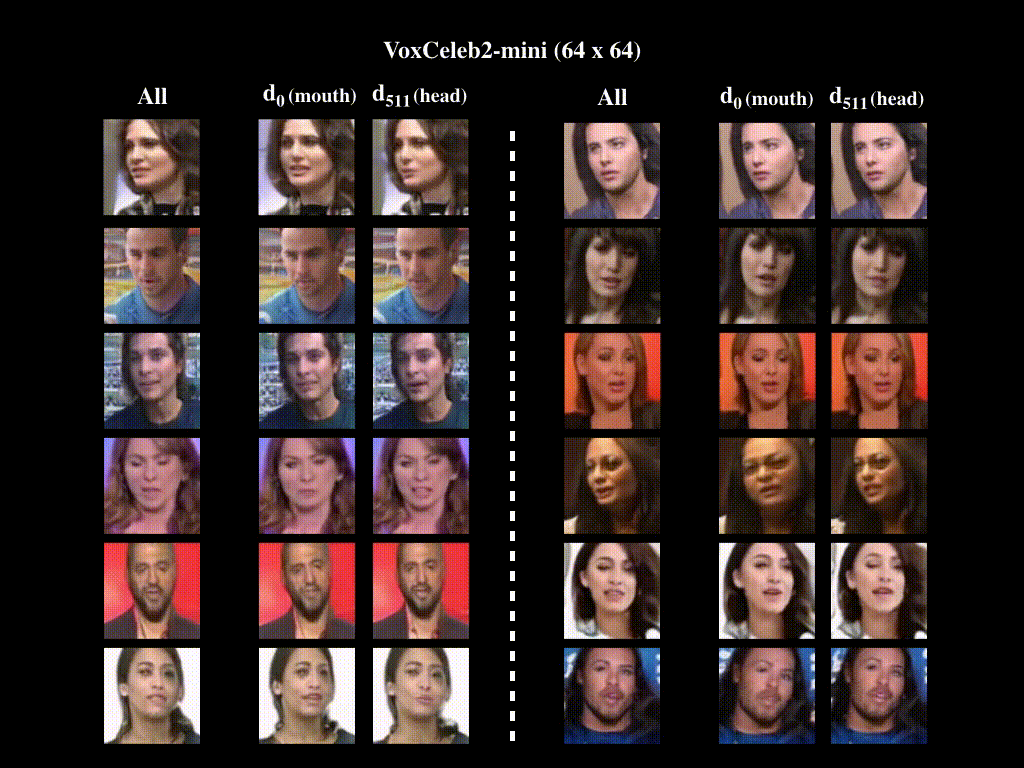
2. Motion Decomposition
All indicates generated videos are obtained by activating all directions in the motion bank, whereas di denotes that only the ith direction has been activated. For VoxCeleb2-mini (128x128), We observe that d2 represents talking, whereas d511 corresponds to head moving. For VoxCeleb2-mini (64x64), we have quantitatively proven in the main paper that motion related to mouth and head are represented by d0 and d511, respectively. Generated videos verify this result. For BAIR-robot, we show generated videos with d1 and d511 activated, respectively. We provide corresponding optical flow videos, which illustrate the moving directions of the robot arm when the two directions are activated. We note that while d1 moves the robot arm back and forth, d511 moves it left and right.
3. Appearance and Motion Disentanglement
For each dataset, we show videos generated by combining one appearance noise vector za and a number of motion noise vectors {zm0,zm1,...,zmT-1}.
4. Linear Interpolation
We linearly interpolate two appearance codes, za0 and za1, and associate each intermediate appearance to one motion code sequence. Results show that intermediate appearances are altered gradually and smoothly. Notably, we observe continuous changes of head pose, age and cloth color in videos related to VoxCeleb2-mini; as well as changes of starting position and background in videos related to BAIR-robot.
5. Controllable Generation
In left part, a linear trajectory is provided for d1 and a sinusoidal trajectory for d511. In right part, d1 and d511 are activated oppositely. We illustrate generated videos by activating d1, d511, as well as both directions, respectively, while all other directions maintain deactivated (set alpha to 0). The related results indicate that the robot arm can indeed be controlled directly with different trajectories.
6. Longer Video Generation
We generate longer videos by providing as input >16 vectors of motion noise sequences for both datasets. Specifically, for BAIR-robot, in each instance we input the size 16, 32 and 48 of zmi, in order to generate videos with different temporal lengths. We note that in generated videos of length about 45 frames the robot arm disappears. For VoxCeleb2-mini, which incorporates more complex motion, we find that after 32 frames, generated frames become blurry and ultimately faces melt.