Video Editing
By combining LEO and ControlNet, generated videos can be editted by only modifying the first frame.
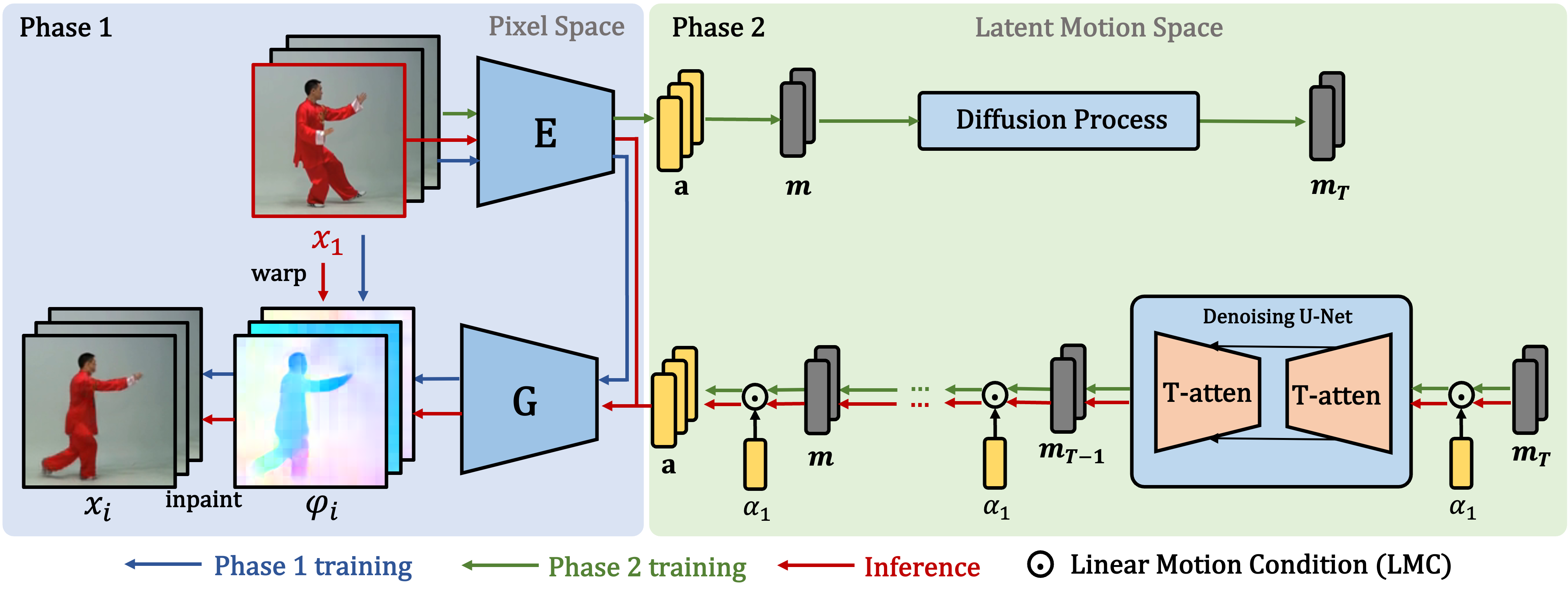
Spatio-temporal coherency is a major challenge in synthesizing high quality videos, particularly in synthesizing human videos that contain rich global and local deformations. To resolve this challenge, previous approaches have resorted to different features in the generation process aimed at representing appearance and motion. However, in the absence of strict mechanisms to guarantee such disentanglement, a separation of motion from appearance has remained challenging, resulting in spatial distortions and temporal jittering that break the spatio-temporal coherency. Motivated by this, we here propose LEO, a novel framework for human video synthesis, placing emphasis on spatio-temporal coherency. Our key idea is to represent motion as a sequence of flow maps in the generation process, which inherently isolate motion from appearance. We implement this idea via a flow-based image animator and a Latent Motion Diffusion Model (LMDM). The former bridges a space of motion codes with the space of flow maps, and synthesizes video frames in a warp-and-inpaint manner. LMDM learns to capture motion prior in the training data by synthesizing sequences of motion codes. Extensive quantitative and qualitative analysis suggests that LEO significantly improves coherent synthesis of human videos over previous methods on the datasets TaichiHD, FaceForensics and CelebV-HQ. In addition, the effective disentanglement of appearance and motion in LEO allows for two additional tasks, namely infinite-length human video synthesis, as well as content-preserving video editing.
Unconditional video generation on Taichi-HD (128 x 128 and 256 x 256) and FaceForensics (256 x 256) datasets.
Given the first frame, LEO is able to generate the following sequences. Results are shown on Taichi-HD (128 x 128 and 256 x 256), FaceForensics (256 x 256) and CelebV (256 x 256) datasets.
Results are shown by using LEO to generate long videos (1024 frames).
LEO is able to disentangle appearance and motion. (Left) same motion, differrent appearance. (Right) same appearance, different motion.
By combining LEO and ControlNet, generated videos can be editted by only modifying the first frame.
@article{wang2023leo,
title={LEO: Generative Latent Image Animator for Human Video Synthesis},
author={Wang, Yaohui and Ma, Xin and Chen, Xinyuan and Dantcheva, Antitza and Dai, Bo and Qiao, Yu},
journal={arXiv preprint arXiv:2305.03989},
year={2023}
}