Latent Image Animator: Learning to Animate Images via Latent Space Navigation
In ICLR 2022
Yaohui Wang Di Yang François Brémond Antitza Dantcheva
Inria, Université Côte d'Azur
[PDF] [arXiv] [Code] [Bibtex]
Abstract
Due to the remarkable progress of deep generative models, animating images has become increasingly efficient, whereas associated results have become increasingly realistic. Current animation-approaches commonly exploit structure representation extracted from driving videos. Such structure representation is instrumental in transferring motion from driving videos to still images. However, such approaches fail in case that a source image and driving video encompass large appearance variation. Moreover, the extraction of structure information requires additional modules that endow the animation-model with increased complexity. Deviating from such models, we here introduce the Latent Image Animator (LIA), a self-supervised autoencoder that evades need for structure representation. LIA is streamlined to animate images by linear navigation in the latent space. Specifically, motion in generated video is constructed by linear displacement of codes in the latent space. Towards this, we learn a set of orthogonal motion directions simultaneously, and use their linear combination, in order to represent any displacement in the latent space. Extensive quantitative and qualitative analysis suggests that our model systematically and significantly outperforms state-of-art methods on VoxCeleb, Taichi and TED-talk datasets w.r.t. generated quality.
Overview
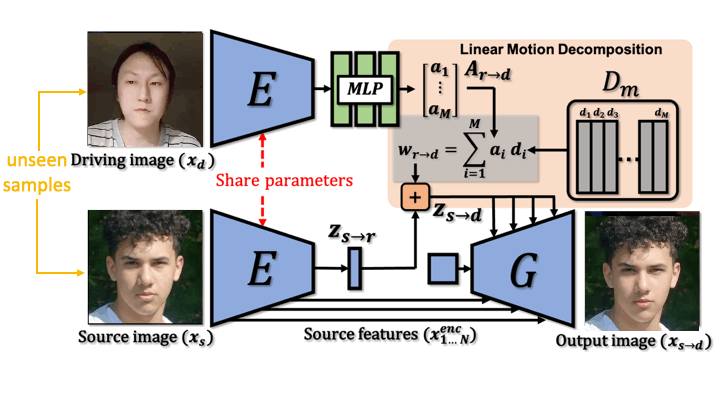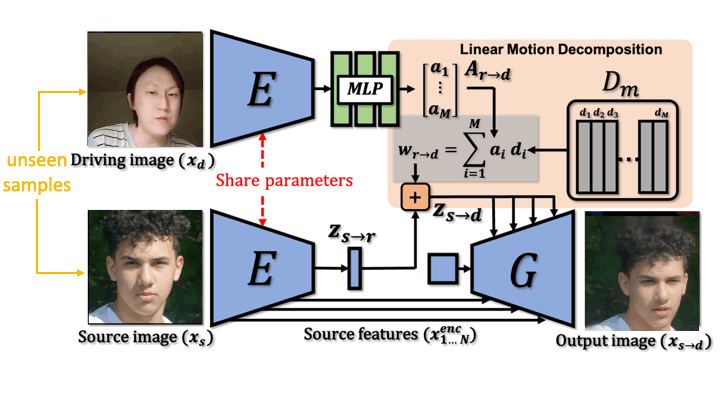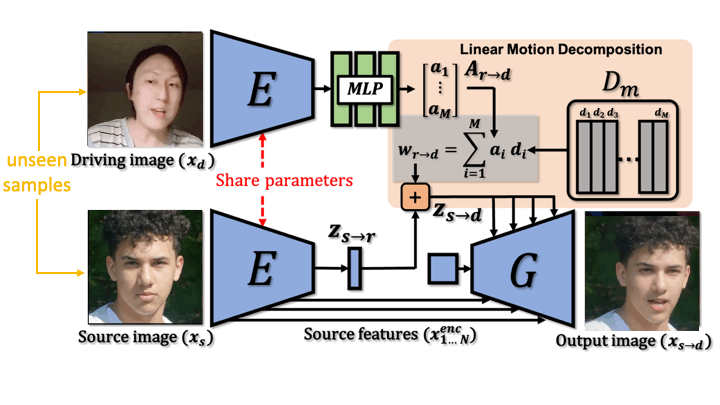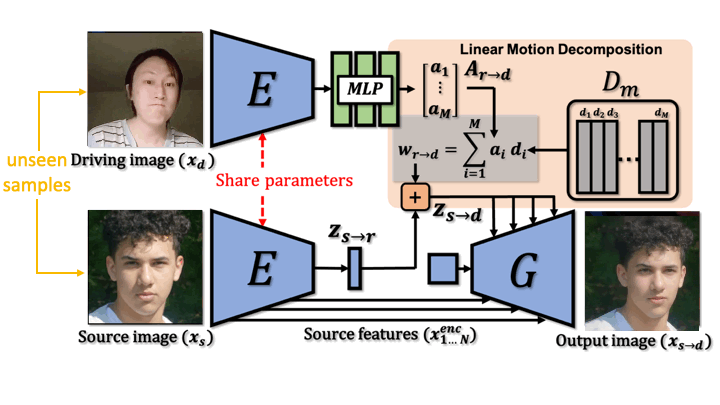
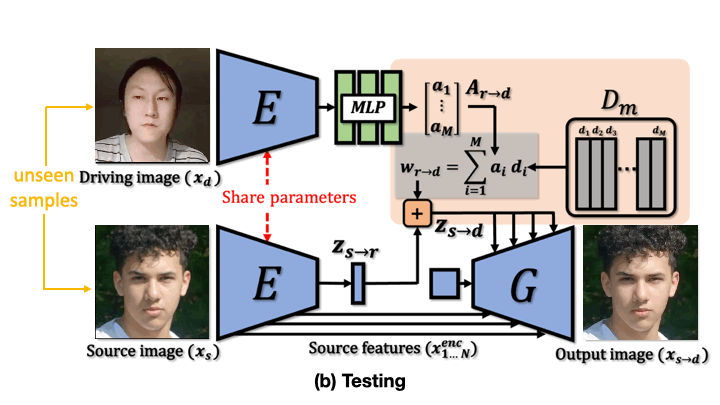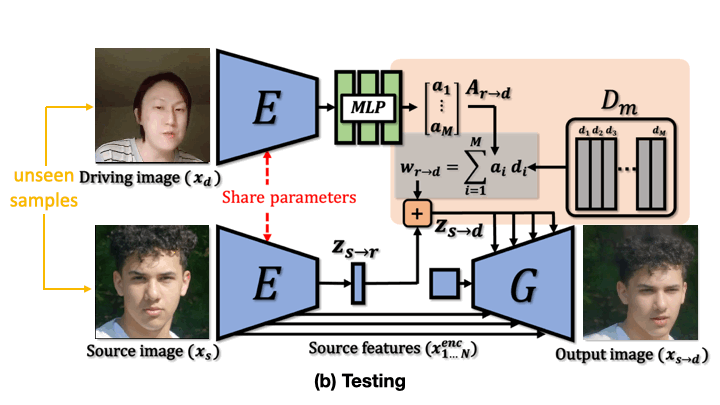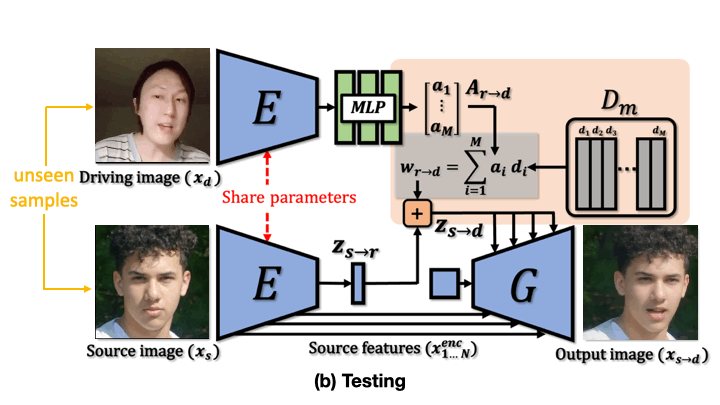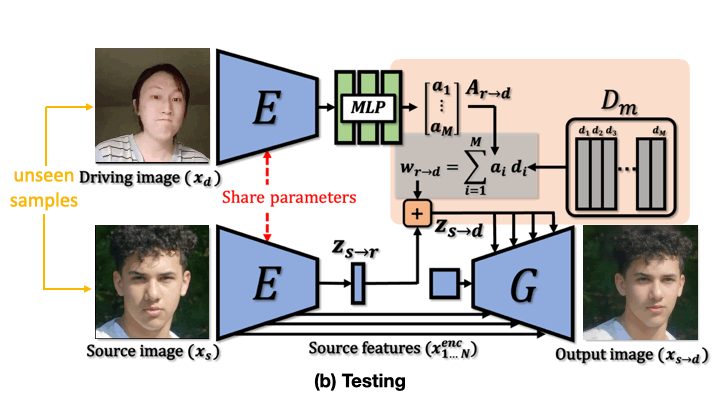
LIA is an autoencoder consisting of two networks, an encoder E and a generator G. In the latent space, we apply Linear Motion Decomposition (LMD) towards learning a motion dictionary, which is an orthogonal basis where each vector represents a basic visual transformation. (a) During training, LIA takes two frames sampled from the same video sequence as source and driving image respectively. (b) In testing time, LIA is able to transfer motion from unseen videos to unseen images without fine-tuning.
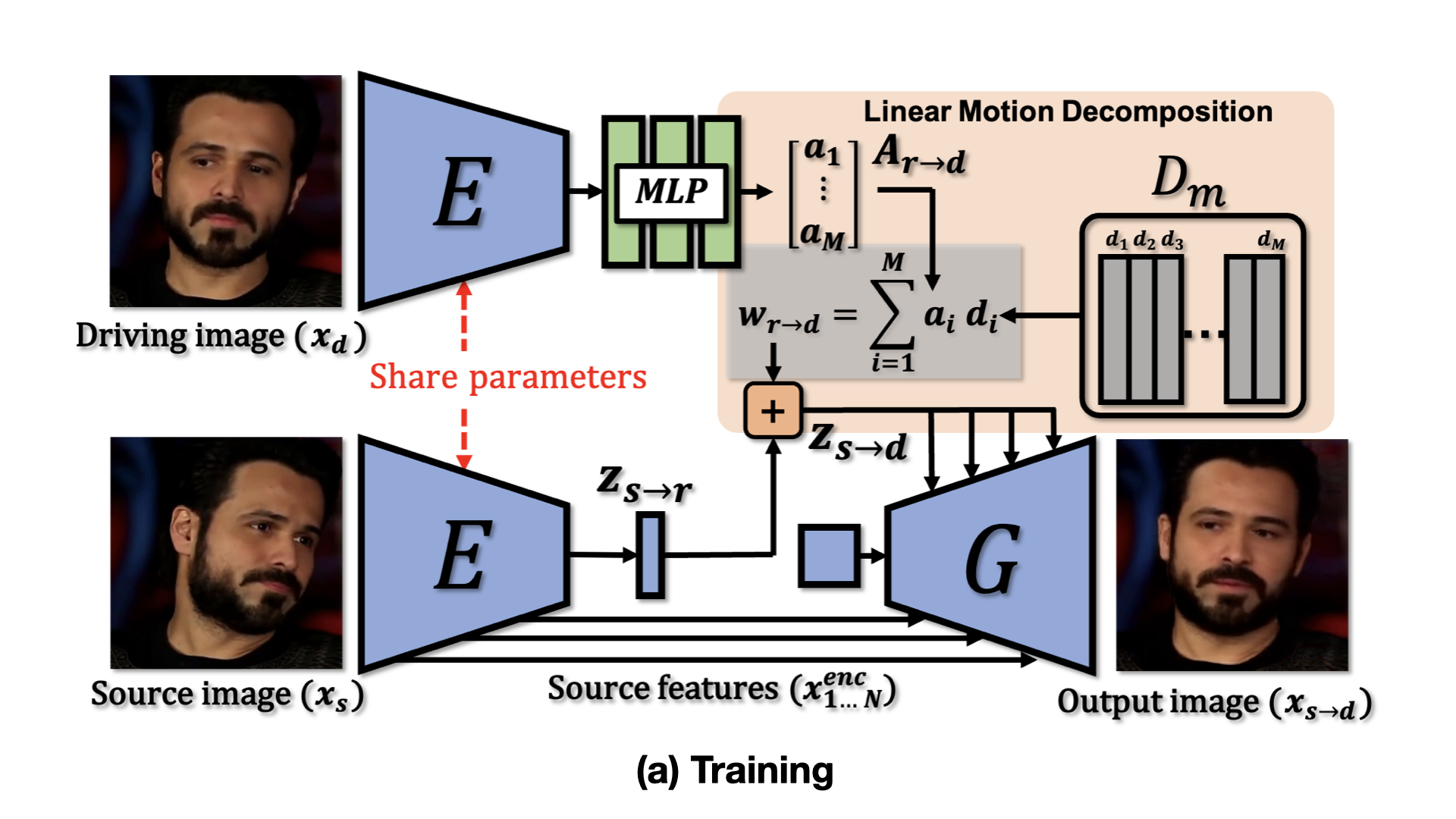
Talking Head Animation
Motion Dictionary Linear Manipulation
Comparison with SOTA
Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation AD011011627R1. It was supported by the French Government, by the National Research Agency (ANR) under Grant ANR-18-CE92-0024, project RESPECT and through the 3IA Côte d’Azur Investments in the Future project managed by the National Research Agency (ANR) with the reference number ANR-19-P3IA-0002.