

I am Research Scientist at Shanghai Artificial Intelligence Laboratory, and adjunct PhD advisor at Shanghai Jiao Tong University. My research focuses on applying machine learning on video generation models to simulate real-world.
I obtained my PhD degree from STARS team at Inria Sophia Antipolis advised by Antitza Dantcheva and Francois Bremond. Prior to that, I completed Master Artificial Intelligence directed by Isabelle Guyon and Michèle Sebag from Université Paris-Saclay.
My works on video generation include LaVie, Latte, SEINE, AnimateDiff and LIA.
I am always seeking self-motivated PhD students and research interns to join my team. Feel free to contact me if you are interested.
News
03 / 2026
1 paper AI killed the video star accepted to IJCV.
05 / 2025
02 / 2025
Research
(*equal contribution, †correspondance & project lead)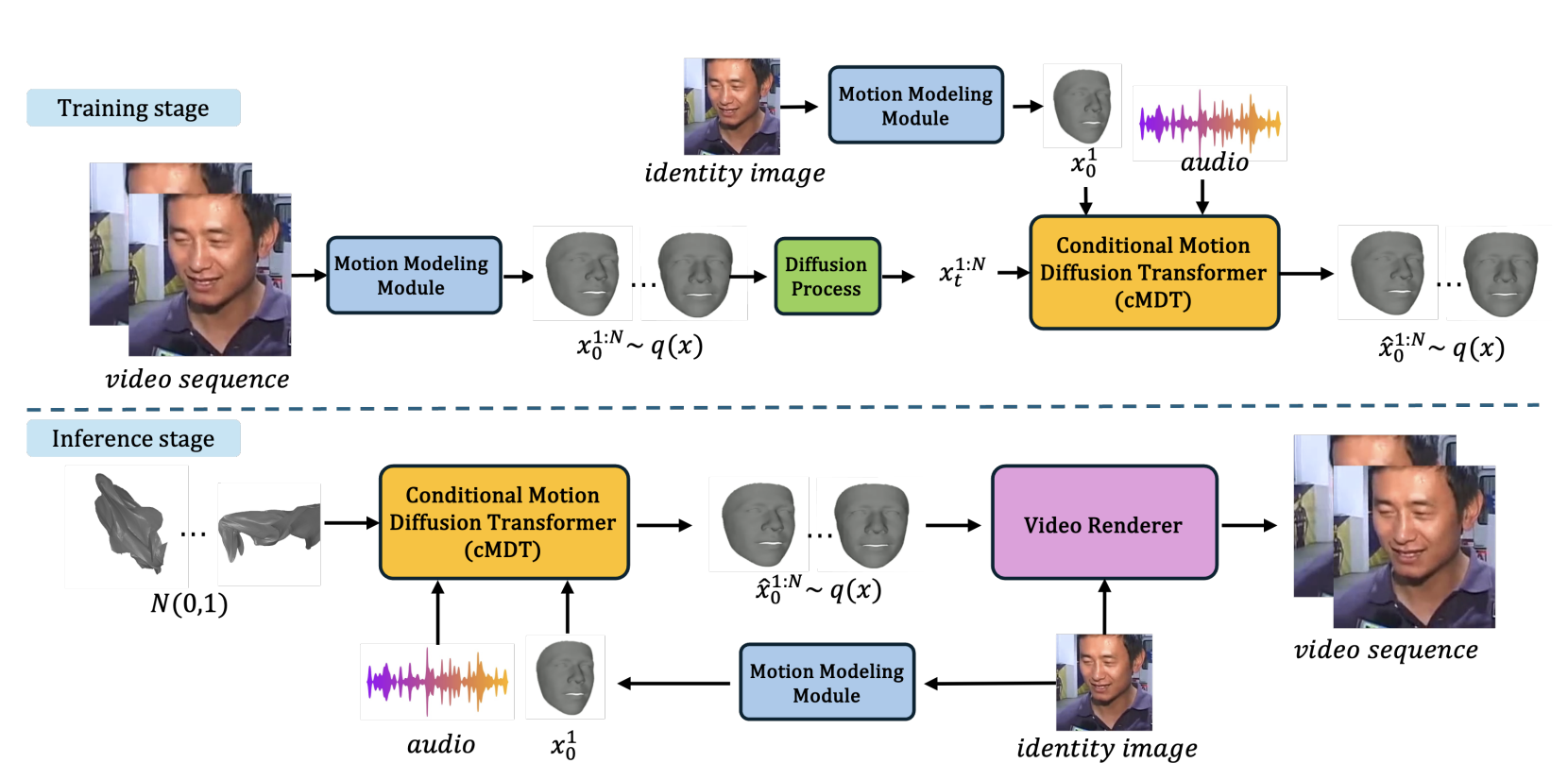
AI killed the video star. Audio-driven diffusion model for expressive talking head generation
Baptiste Chopin, Tashvik Dhamija, Pranav Balaji, Yaohui Wang†, Antitza Dantcheva
In IJCV 2026 Paper | Arxiv | Project page | Code |
Baptiste Chopin, Tashvik Dhamija, Pranav Balaji, Yaohui Wang†, Antitza Dantcheva
In IJCV 2026 Paper | Arxiv | Project page | Code |

LIA-X: Interpretable Latent Portrait Animator
Yaohui Wang, Di Yang, Xinyuan Chen, Francois Bremond, Yu Qiao, Antitza Dantcheva
In arXiv 2025 Paper | Arxiv | Project page | Code |
Yaohui Wang, Di Yang, Xinyuan Chen, Francois Bremond, Yu Qiao, Antitza Dantcheva
In arXiv 2025 Paper | Arxiv | Project page | Code |

ShotDirector: Directorially Controllable Multi-Shot Video Generation with Cinematographic Transitions
Xiaoxue Wu, Xinyuan Chen, Yaohui Wang, Yu Qiao
In CVPR 2026 Paper | Arxiv | Project page | Code |
Xiaoxue Wu, Xinyuan Chen, Yaohui Wang, Yu Qiao
In CVPR 2026 Paper | Arxiv | Project page | Code |

VDOT: Efficient Unified Video Creation via Optimal Transport Distillation
Yutong Wang, Haiyu Zhang, Tianfan Xue, Yu Qiao, Yaohui Wang, Chang Xu, Xinyuan Chen
In CVPR 2026 Paper | Arxiv | Project page | Code |
Yutong Wang, Haiyu Zhang, Tianfan Xue, Yu Qiao, Yaohui Wang, Chang Xu, Xinyuan Chen
In CVPR 2026 Paper | Arxiv | Project page | Code |
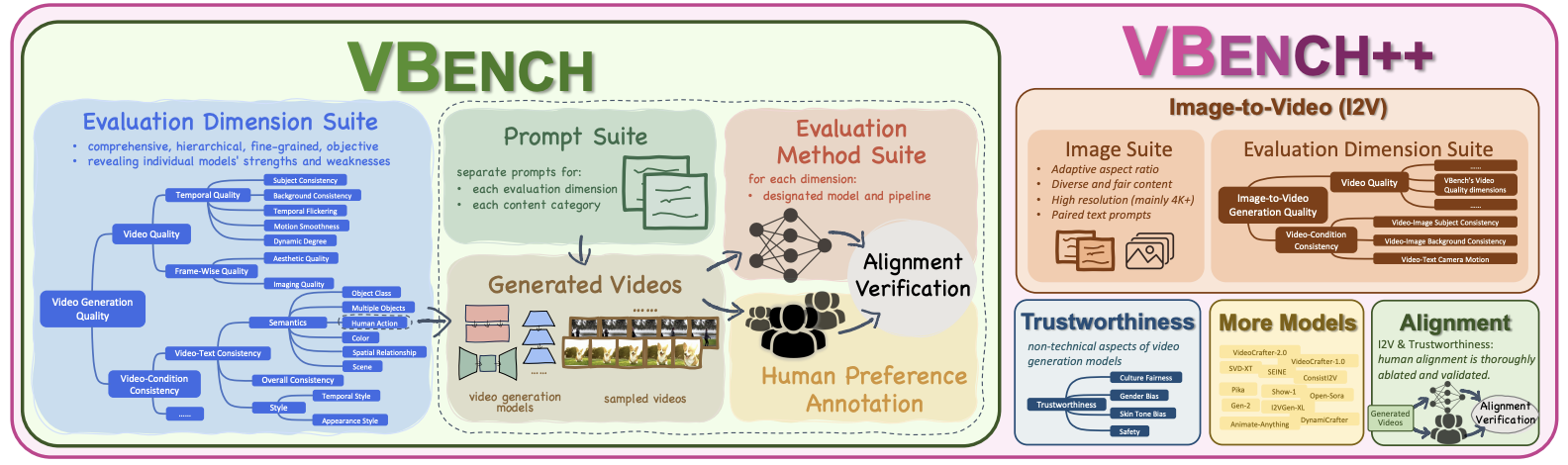
Vbench++: Comprehensive and versatile benchmark suite for video generative models
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
In TPAMI 2025 Paper | Arxiv | Project page | Code |
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
In TPAMI 2025 Paper | Arxiv | Project page | Code |
Cinetrans: Learning to generate videos with cinematic transitions via masked diffusion models
Xiaoxue Wu, Bingjie Gao, Yu Qiao, Yaohui Wang, Xinyuan Chen
In ICLR 2026 Paper | Arxiv | Project page | Code |
Xiaoxue Wu, Bingjie Gao, Yu Qiao, Yaohui Wang, Xinyuan Chen
In ICLR 2026 Paper | Arxiv | Project page | Code |

RAPO++: Cross-Stage Prompt Optimization for Text-to-Video Generation via Data Alignment and Test-Time Scaling
Bingjie Gao, Qianli Ma, Xiaoxue Wu, Shuai Yang, Guanzhou Lan, Haonan Zhao, Jiaxuan Chen, Qingyang Liu, Yu Qiao, Xinyuan Chen, Yaohui Wang, Li Niu
In arXiv 2025 Paper | Arxiv | Project page | Code |
Bingjie Gao, Qianli Ma, Xiaoxue Wu, Shuai Yang, Guanzhou Lan, Haonan Zhao, Jiaxuan Chen, Qingyang Liu, Yu Qiao, Xinyuan Chen, Yaohui Wang, Li Niu
In arXiv 2025 Paper | Arxiv | Project page | Code |

GenHOI: Generalizing Text-driven 4D Human-Object Interaction Synthesis for Unseen Objects
Shujia Li, Haiyu Zhang, Xinyuan Chen, Yaohui Wang†, Yutong Ban†
In arXiv 2025 Paper | Arxiv | Project page | Code |
Shujia Li, Haiyu Zhang, Xinyuan Chen, Yaohui Wang†, Yutong Ban†
In arXiv 2025 Paper | Arxiv | Project page | Code |

AccVideo: Accelerating Video Diffusion Model with Synthetic Dataset
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
In arXiv 2025 Paper | Arxiv | Project page | Code | Hugging face
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
In arXiv 2025 Paper | Arxiv | Project page | Code | Hugging face

Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang†, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-fang Li, Cunjian Chen, Yu Qiao
In TMLR 2025 Paper | Arxiv | Project page | Code | Hugging face
Xin Ma, Yaohui Wang†, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-fang Li, Cunjian Chen, Yu Qiao
In TMLR 2025 Paper | Arxiv | Project page | Code | Hugging face
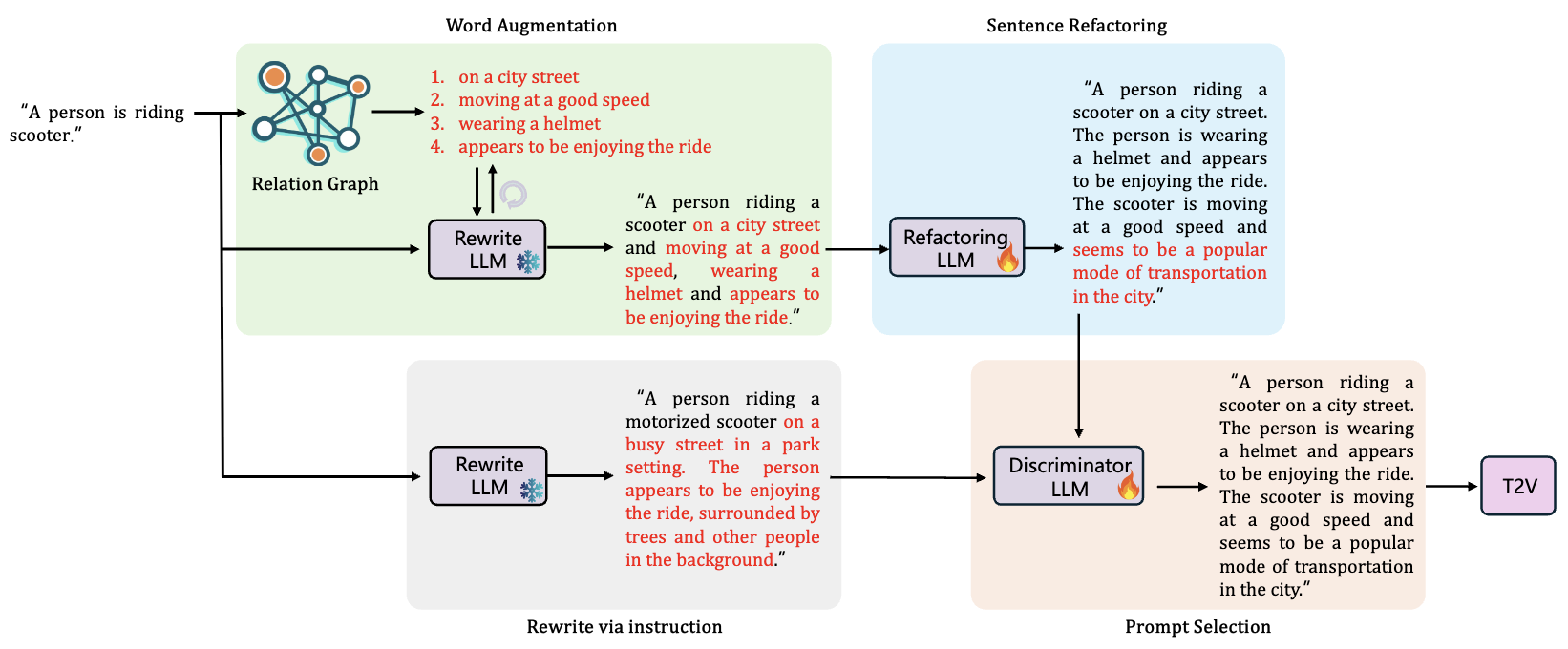
The Devil is in the Prompts: Retrieval-Augmented Prompt Optimization for Text-to-Video Generation
Bingjie Gao, Xinyu Gao, Xiaoxue Wu, Yujie Zhou, Yu Qiao†, Li Niu†, Xinyuan Chen†, Yaohui Wang†
In Proc. CVPR, Nashville, 2025 Paper | Arxiv | Project page | Code | Hugging face
Bingjie Gao, Xinyu Gao, Xiaoxue Wu, Yujie Zhou, Yu Qiao†, Li Niu†, Xinyuan Chen†, Yaohui Wang†
In Proc. CVPR, Nashville, 2025 Paper | Arxiv | Project page | Code | Hugging face

Ouroboros3D: Image-to-3D Generation via 3D-aware Recursive Diffusion
Hao Wen, Zehuan Huang, Yaohui Wang, Xinyuan Chen, Lu Sheng
In Proc. CVPR, Nashville, 2025 Paper | Arxiv | Project page | Code | Hugging face
Hao Wen, Zehuan Huang, Yaohui Wang, Xinyuan Chen, Lu Sheng
In Proc. CVPR, Nashville, 2025 Paper | Arxiv | Project page | Code | Hugging face

LaVie: High-Quality Video Generation with Cascaded Latent Diffusion Models
Yaohui Wang*, Xinyuan Chen*, Xin Ma*, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, Yuwei Guo, Tianxing Wu, Chenyang Si, Yuming Jiang, Cunjian Chen, Chen Change Loy, Bo Dai, Dahua Lin†, Yu Qiao†, Ziwei Liu†
In IJCV 2024 Paper | Arxiv | Project page | Code | Hugging face
Yaohui Wang*, Xinyuan Chen*, Xin Ma*, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, Yuwei Guo, Tianxing Wu, Chenyang Si, Yuming Jiang, Cunjian Chen, Chen Change Loy, Bo Dai, Dahua Lin†, Yu Qiao†, Ziwei Liu†
In IJCV 2024 Paper | Arxiv | Project page | Code | Hugging face

Cinemo: Consistent and Controllable Image Animation with Motion Diffusion Models
Xin Ma, Yaohui Wang†, Gengyun Jia, Xinyuan Chen, Tien-Tsin Wong, Yuan-fang Li, Cunjian Chen†
In Proc. CVPR, Nashville, 2025 Consistent and Controllable Image Animation with Motion Linear Diffusion Transformers
Xin Ma, Yaohui Wang†, Gengyun Jia, Xinyuan Chen, Tien-Tsin Wong, Cunjian Chen†
In TPAMI, 2026 Paper | Paper(TPAMI version) | Arxiv | Project page | Code | Hugging face
Xin Ma, Yaohui Wang†, Gengyun Jia, Xinyuan Chen, Tien-Tsin Wong, Yuan-fang Li, Cunjian Chen†
In Proc. CVPR, Nashville, 2025 Consistent and Controllable Image Animation with Motion Linear Diffusion Transformers
Xin Ma, Yaohui Wang†, Gengyun Jia, Xinyuan Chen, Tien-Tsin Wong, Cunjian Chen†
In TPAMI, 2026 Paper | Paper(TPAMI version) | Arxiv | Project page | Code | Hugging face

4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao†
In Proc. NeurIPS, Vancouver, 2024 Paper | Arxiv | Project page | Code
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao†
In Proc. NeurIPS, Vancouver, 2024 Paper | Arxiv | Project page | Code

SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction
Xinyuan Chen*, Yaohui Wang*, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin†, Yu Qiao†, Ziwei Liu†
In Proc. ICLR, Vienna, 2024 Paper | Arxiv | Project page | Code | Hugging face
Xinyuan Chen*, Yaohui Wang*, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin†, Yu Qiao†, Ziwei Liu†
In Proc. ICLR, Vienna, 2024 Paper | Arxiv | Project page | Code | Hugging face
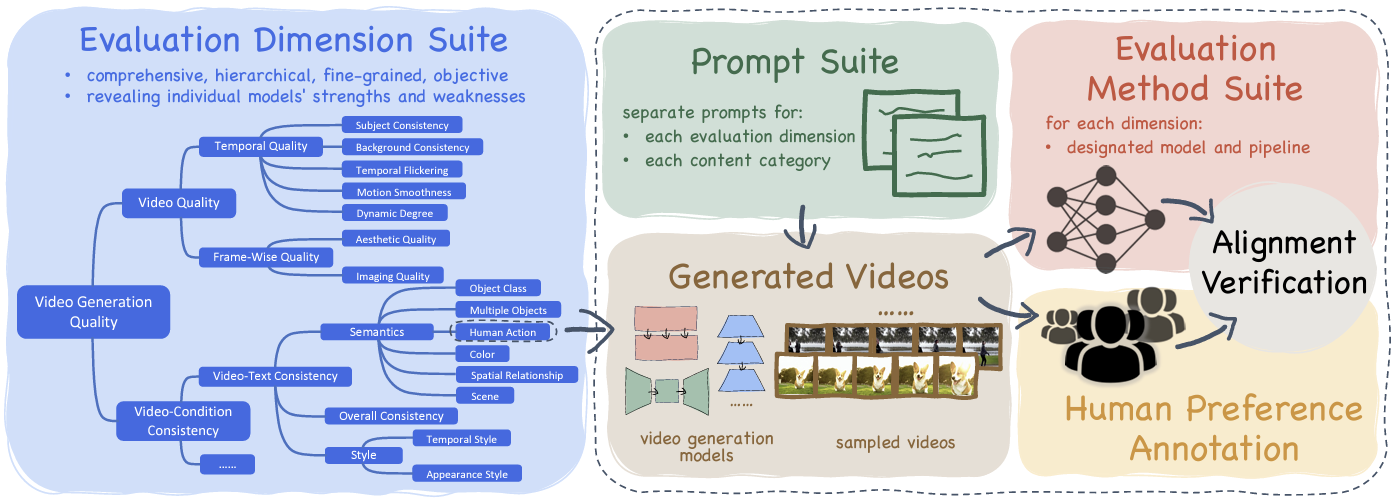
VBench: Comprehensive Benchmark Suite for Video Generative Models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao and Ziwei Liu
In Proc. CVPR, Seattle, 2024 Paper | Arxiv | Project page | Code
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao and Ziwei Liu
In Proc. CVPR, Seattle, 2024 Paper | Arxiv | Project page | Code

EpiDiff:Enhancing Multi-View Synthesis via Localized Epipolar-Constrained Diffusion
Zehuan Huang, Hao Wen, Junting Dong, Yaohui Wang, Yangguang Li, Xinyuan Chen, Yan-pei Cao, Ding Liang, Yu Qiao, Bo Dai and Lu Sheng
In Proc. CVPR, Seattle, 2024 Paper | Arxiv | Project page | Code
Zehuan Huang, Hao Wen, Junting Dong, Yaohui Wang, Yangguang Li, Xinyuan Chen, Yan-pei Cao, Ding Liang, Yu Qiao, Bo Dai and Lu Sheng
In Proc. CVPR, Seattle, 2024 Paper | Arxiv | Project page | Code
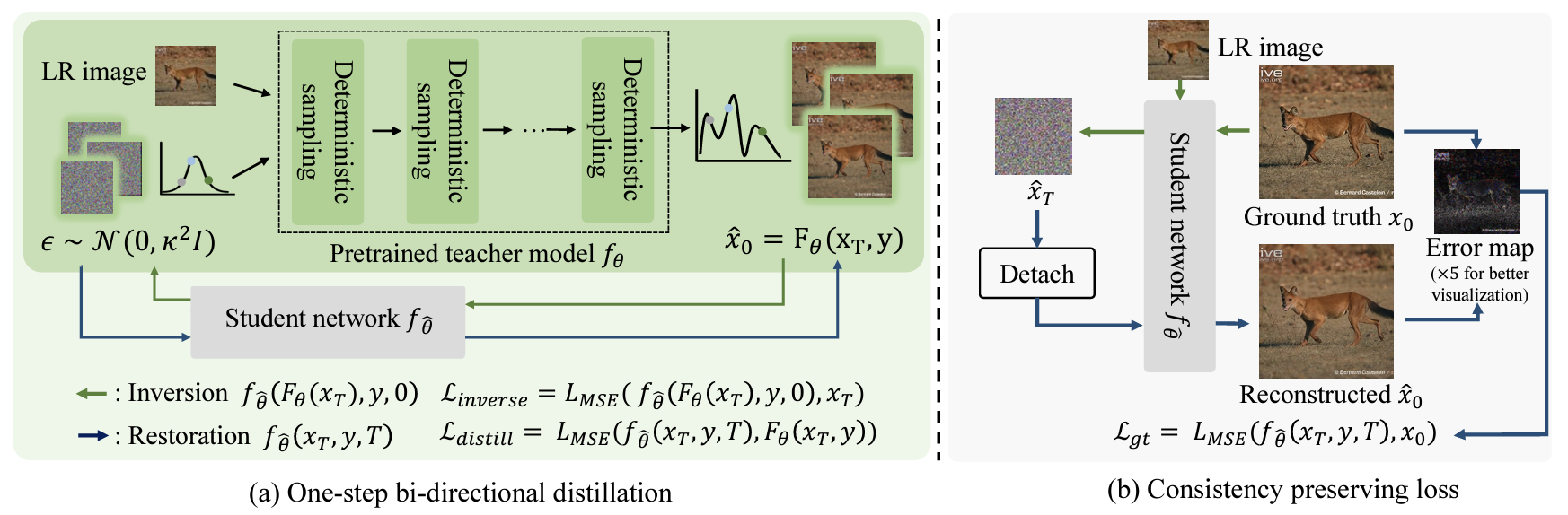
SinSR: Diffusion-Based Image Super-Resolution in a Single Step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C. Kot and Bihan Wen
In Proc. CVPR, Seattle, 2024 Paper | Arxiv | Project page | Code
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C. Kot and Bihan Wen
In Proc. CVPR, Seattle, 2024 Paper | Arxiv | Project page | Code
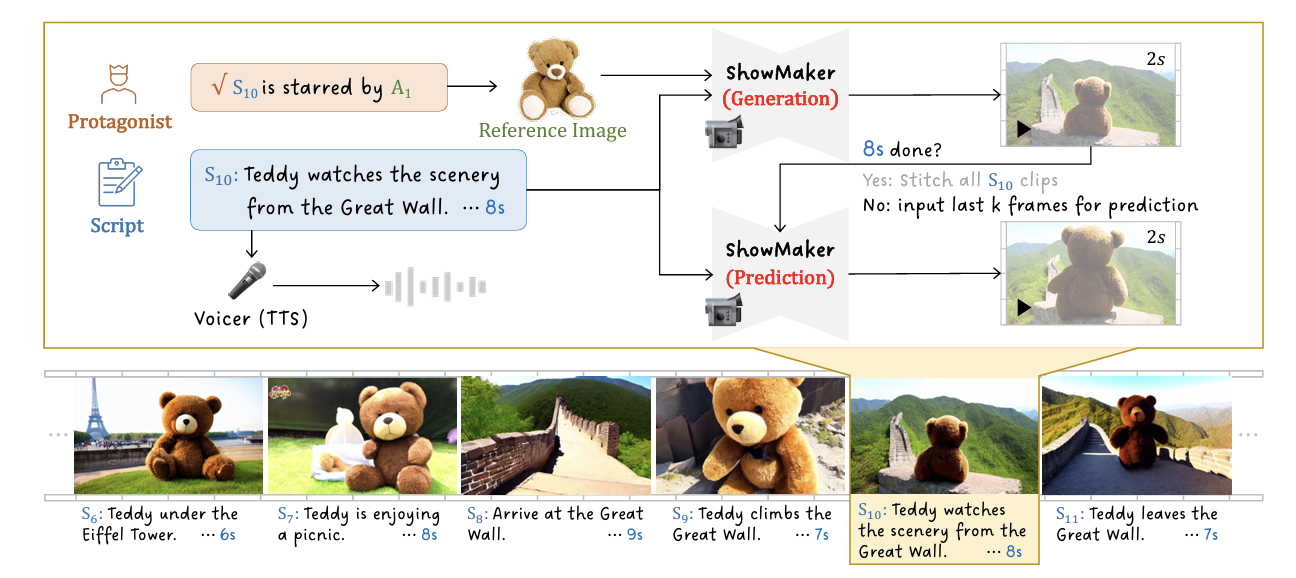
Vlogger: Make Your Dream A Vlog
Shaobin Zhuang, Kunchang Li, Xinyuan Chen, Yaohui Wang, Ziwei Liu, Yu Qiao, Yali Wang
In Proc. CVPR, Seattle, 2024 Paper | Arxiv | Project page | Code
Shaobin Zhuang, Kunchang Li, Xinyuan Chen, Yaohui Wang, Ziwei Liu, Yu Qiao, Yali Wang
In Proc. CVPR, Seattle, 2024 Paper | Arxiv | Project page | Code

Brush Your Text: Synthesize Any Scene Text on Images via Diffusion Model
Lingjun Zhang, Xinyuan Chen, Yaohui Wang, Yue Lu, Yu Qiao
In Proc. AAAI, Vancouver, 2024 Paper | Arxiv | Project page | Code
Lingjun Zhang, Xinyuan Chen, Yaohui Wang, Yue Lu, Yu Qiao
In Proc. AAAI, Vancouver, 2024 Paper | Arxiv | Project page | Code
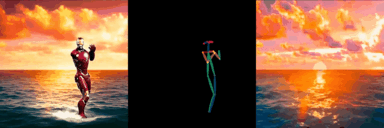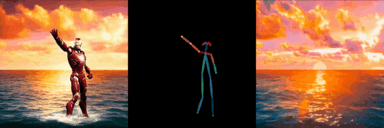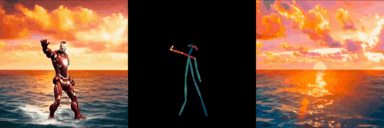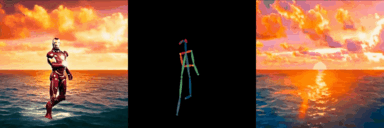
ConditionVideo: Training-Free Condition-Guided Text-to-Video Generation
Bo Peng, Xinyuan Chen, Yaohui Wang, Chaochao Lu, Yu Qiao
In Proc. AAAI, Vancouver, 2024 Paper | Arxiv | Project page | Code
Bo Peng, Xinyuan Chen, Yaohui Wang, Chaochao Lu, Yu Qiao
In Proc. AAAI, Vancouver, 2024 Paper | Arxiv | Project page | Code
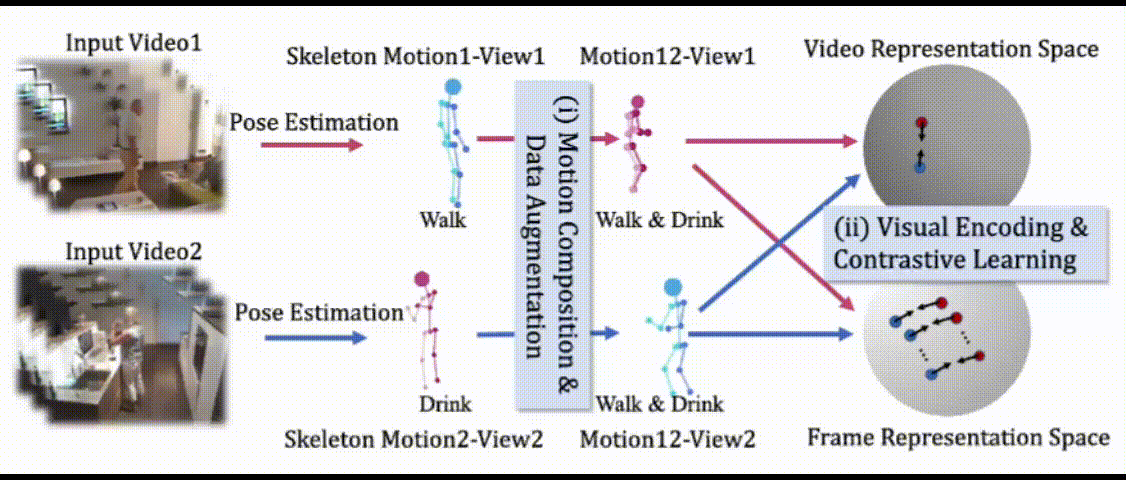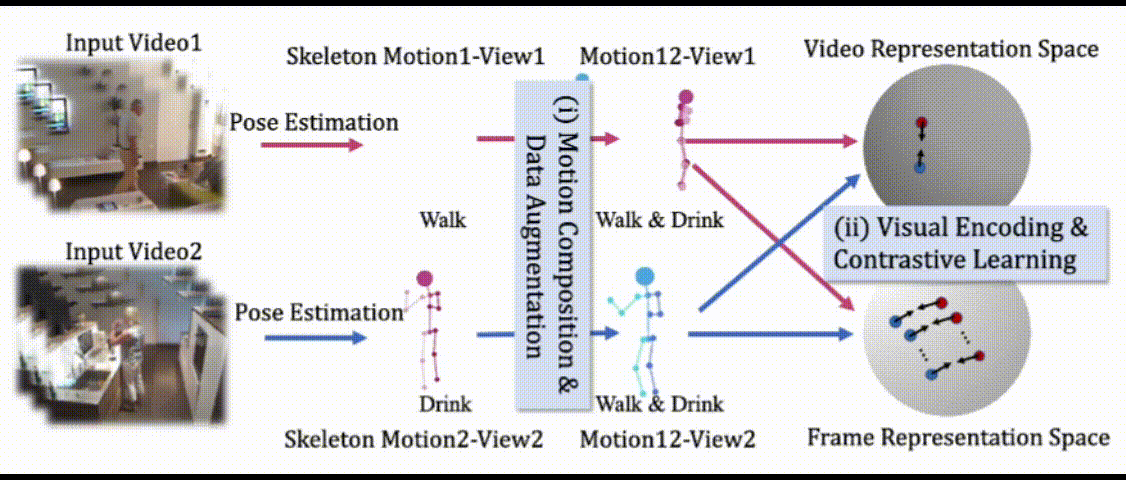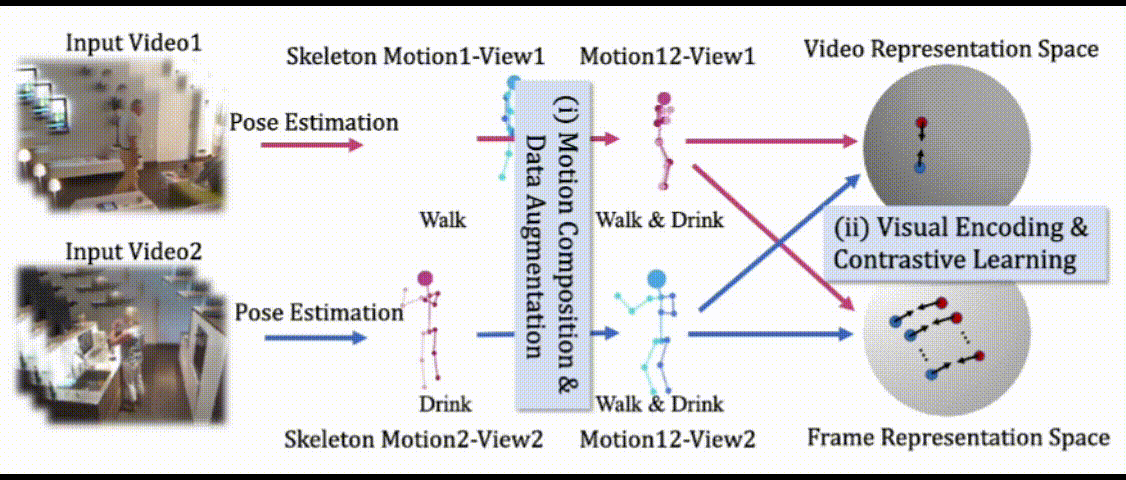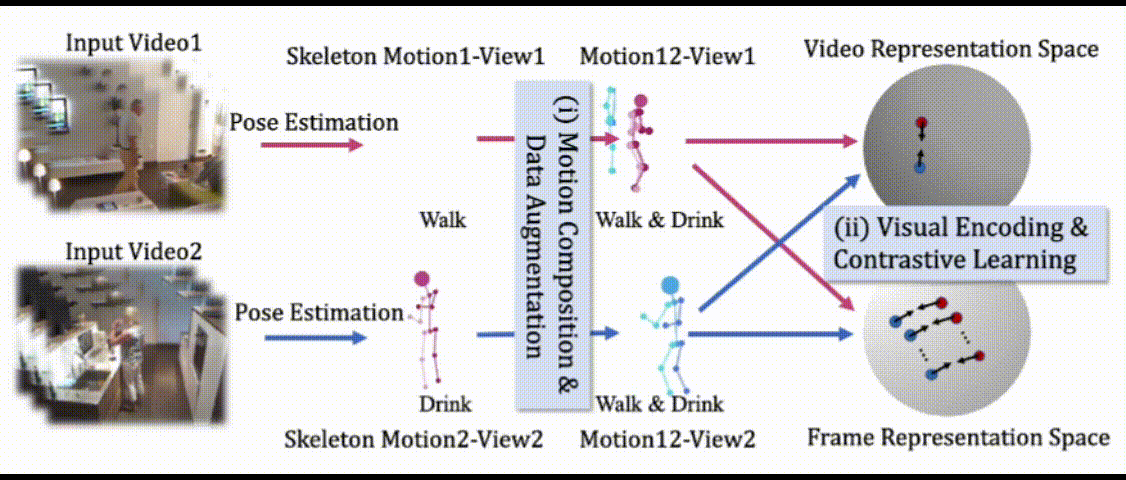
LAC: Latent Action Composition for Skeleton-based Action Segmentation
Di Yang, Yaohui Wang†, Antitza Dantcheva, Quan Kong, Lorenzo Garattoni, Gianpiero Francesca, Francois Bremond. †corresponding author
In Proc. ICCV, Paris, 2023 Paper | Arxiv | Project page | Code
Di Yang, Yaohui Wang†, Antitza Dantcheva, Quan Kong, Lorenzo Garattoni, Gianpiero Francesca, Francois Bremond. †corresponding author
In Proc. ICCV, Paris, 2023 Paper | Arxiv | Project page | Code

InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Yi Wang*, Yinan He*, Yuzhuo Li*, Kunchang Li, Jiashuo Yu, Xin Ma, Xinyuan Chen, Yaohui Wang, Ping Luo, Ziwei Liu, Yali Wang†, Limin Wang†, Yu Qiao†
In Proc. ICLR, Vienna, 2024 Paper | Arxiv | Project page | Code
Yi Wang*, Yinan He*, Yuzhuo Li*, Kunchang Li, Jiashuo Yu, Xin Ma, Xinyuan Chen, Yaohui Wang, Ping Luo, Ziwei Liu, Yali Wang†, Limin Wang†, Yu Qiao†
In Proc. ICLR, Vienna, 2024 Paper | Arxiv | Project page | Code

AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, Bo Dai
In Proc. ICLR, Vienna, 2024 Paper | Arxiv | Project page | Code
Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, Bo Dai
In Proc. ICLR, Vienna, 2024 Paper | Arxiv | Project page | Code

LEO: Generative Latent Image Animator for Human Video Synthesis
Yaohui Wang, Xin Ma, Xinyuan Chen, Cunjian Chen, Antitza Dancheva, Bo Dai, Yu Qiao
In IJCV 2024 Paper | Arxiv | Project page | Code
Yaohui Wang, Xin Ma, Xinyuan Chen, Cunjian Chen, Antitza Dancheva, Bo Dai, Yu Qiao
In IJCV 2024 Paper | Arxiv | Project page | Code

Hierarchical Diffusion Autoencoders and Disentangled Image Manipulation
Zeyu Lu, Chengyue Wu, Xinyuan Chen, Yaohui Wang, Lei Bai, Yu Qiao, Xihui Liu
In Proc. WACV, Hawaii, 2024 Paper | Arxiv | Project page | Code
Zeyu Lu, Chengyue Wu, Xinyuan Chen, Yaohui Wang, Lei Bai, Yu Qiao, Xihui Liu
In Proc. WACV, Hawaii, 2024 Paper | Arxiv | Project page | Code
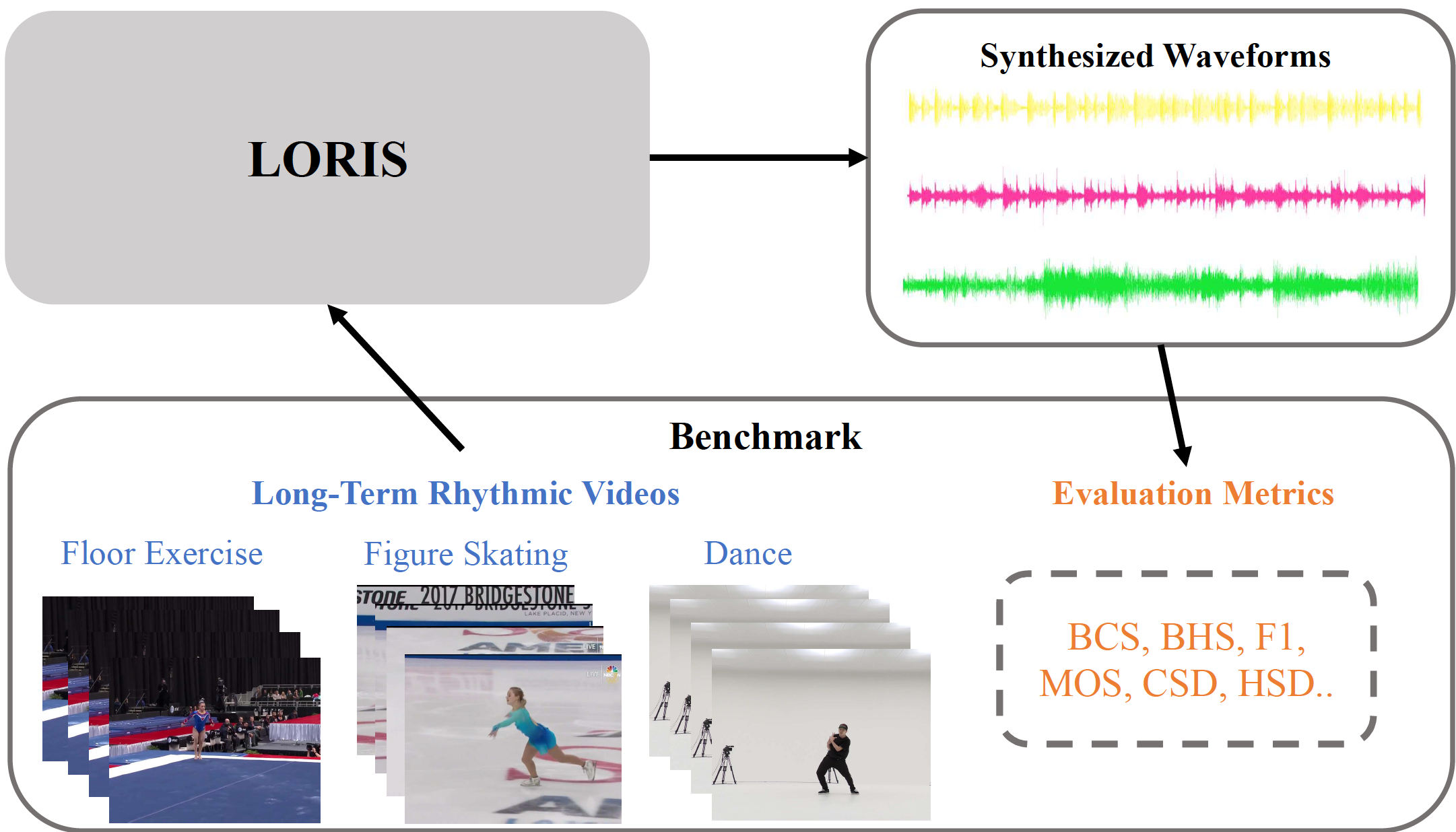
Long-Term Rhythmic Video Soundtracker
Jiashuo Yu, Yaohui Wang, Xinyuan Chen, Xiao Sun, Yu Qiao
In Proc. ICML, Hawaii, 2023 Paper | Arxiv | Project page | Code
Jiashuo Yu, Yaohui Wang, Xinyuan Chen, Xiao Sun, Yu Qiao
In Proc. ICML, Hawaii, 2023 Paper | Arxiv | Project page | Code
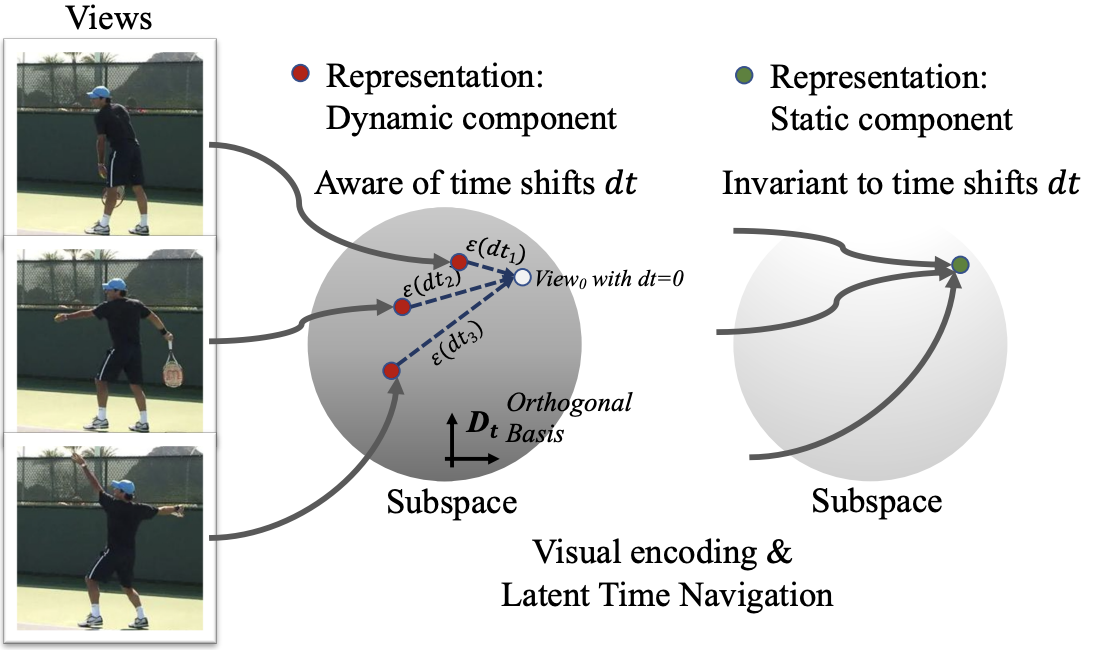
Self-supervised Video Representation Learning via Latent Time Navigation
Di Yang, Yaohui Wang, Quan Kong, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca and François Brémond
In Proc. AAAI, Washington, 2023 Paper | Arxiv | Project page | Code
Di Yang, Yaohui Wang, Quan Kong, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca and François Brémond
In Proc. AAAI, Washington, 2023 Paper | Arxiv | Project page | Code
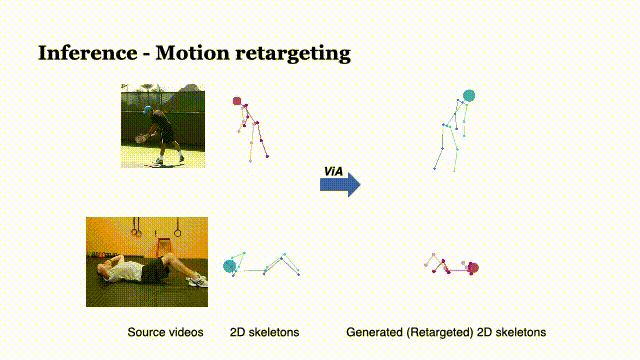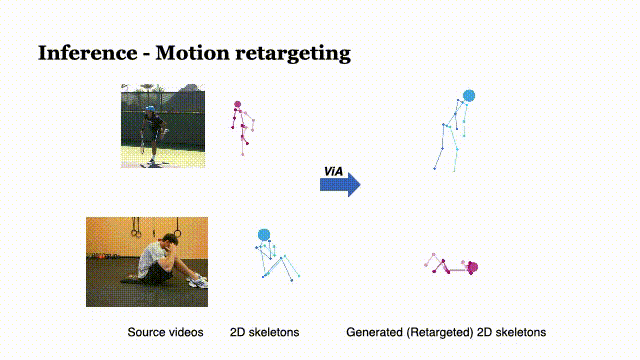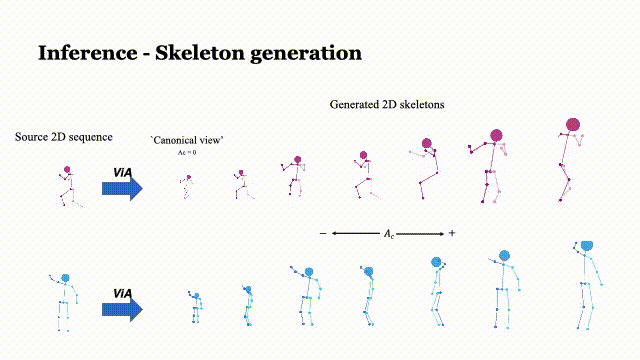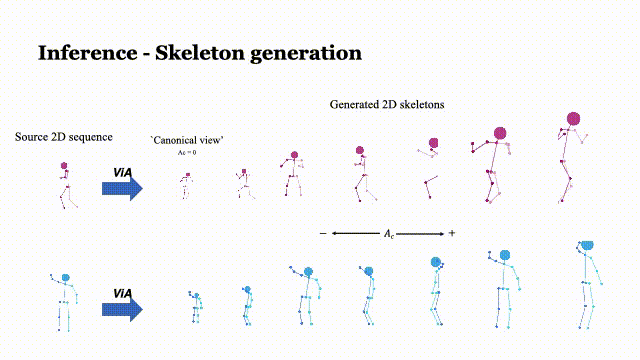
ViA: View-invariant Skeleton Action Representation Learning via Motion Retargeting
Di Yang, Yaohui Wang†, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca and François Brémond
In IJCV, 2023 Paper | Arxiv | Project page | Code
Di Yang, Yaohui Wang†, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca and François Brémond
In IJCV, 2023 Paper | Arxiv | Project page | Code

Latent Image Animator: Learning to Animate Images via Latent Space Navigation
Yaohui Wang, Di Yang, Francois Bremond and Antitza Dantcheva
In Proc. ICLR, Virtual, 2022 LIA: Latent Image Animator
Yaohui Wang, Di Yang, Francois Bremond and Antitza Dantcheva
In TPAMI, 2024 Paper | Paper (TPAMI version) | Arxiv | Project page | Code
Yaohui Wang, Di Yang, Francois Bremond and Antitza Dantcheva
In Proc. ICLR, Virtual, 2022 LIA: Latent Image Animator
Yaohui Wang, Di Yang, Francois Bremond and Antitza Dantcheva
In TPAMI, 2024 Paper | Paper (TPAMI version) | Arxiv | Project page | Code
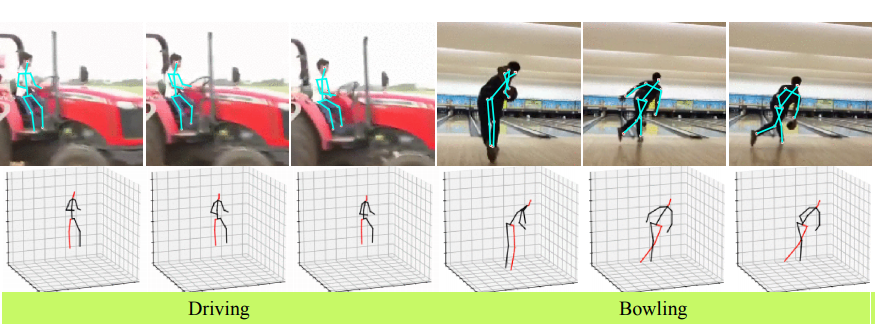
UNIK: A Unified Framework for Real-world Skeleton-based Action Recognition
Di Yang*, Yaohui Wang*, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca and Francois Bremond. *equal contribution
In Proc. BMVC, Virtual, 2021 (Oral) Paper | Arxiv | Project page | Code
Di Yang*, Yaohui Wang*, Antitza Dantcheva, Lorenzo Garattoni, Gianpiero Francesca and Francois Bremond. *equal contribution
In Proc. BMVC, Virtual, 2021 (Oral) Paper | Arxiv | Project page | Code

InMoDeGAN: Interpretable Motion Decomposition Generative Adversarial Network for Video Generation
Yaohui Wang, Francois Bremond, and Antitza Dantcheva
arXiv:2101.03049 Arxiv | Project page | Code
Yaohui Wang, Francois Bremond, and Antitza Dantcheva
arXiv:2101.03049 Arxiv | Project page | Code
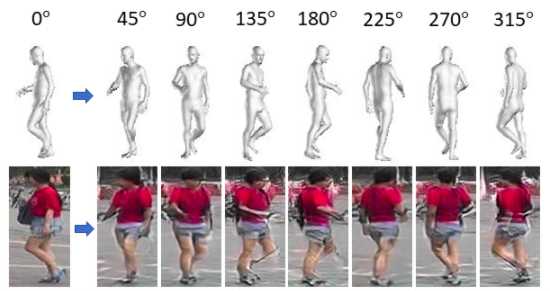
Joint Generative and Contrastive Learning for Unsupervised Person Re-identification
Hao Chen*, Yaohui Wang*, Benoit Lagadec, Antitza Dantcheva, and Francois Bremond. *equal contribution
In Proc. CVPR, Virtual, 2021.
Paper | Code
Learning Invariance from Generated Variance or Unsupervised Person Re-identification
In IEEE TPAMI, 2022.
Paper | Code
Hao Chen*, Yaohui Wang*, Benoit Lagadec, Antitza Dantcheva, and Francois Bremond. *equal contribution
In Proc. CVPR, Virtual, 2021.
Paper | Code
Learning Invariance from Generated Variance or Unsupervised Person Re-identification
In IEEE TPAMI, 2022.
Paper | Code


G³AN: Disentangling appearance and motion for video generation
Yaohui Wang, Piotr Bilinski, Francois Bremond, and Antitza Dantcheva
In Proc. CVPR, Seattle, US, 2020.
In LUV-CVPR Workshop, Seattle, US, 2020. (Oral Presentation)
Paper | Project page | Code | Video
Yaohui Wang, Piotr Bilinski, Francois Bremond, and Antitza Dantcheva
In Proc. CVPR, Seattle, US, 2020.
In LUV-CVPR Workshop, Seattle, US, 2020. (Oral Presentation)
Paper | Project page | Code | Video

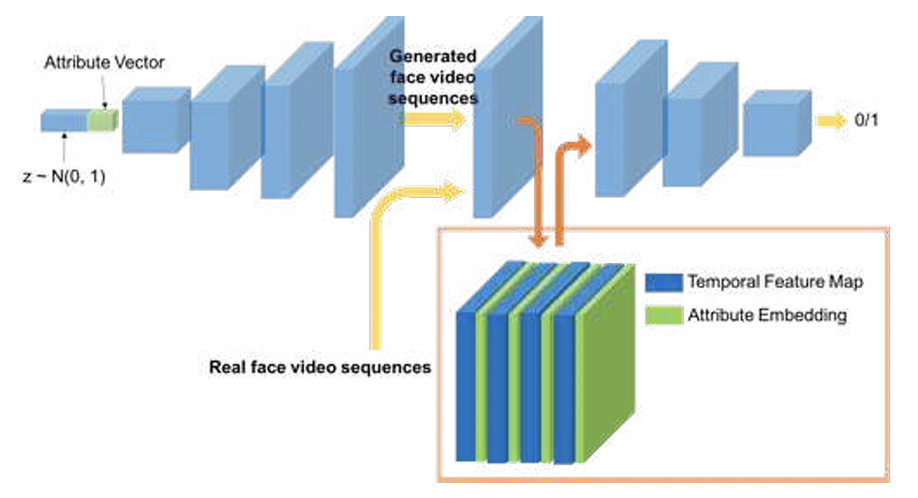
A video is worth more than 1000 lies. Comparing 3DCNN approaches for detecting deepfakes
Yaohui Wang and Antitza Dantcheva
In Proc. FG, Buenos Aires, Argentina, 2020.
Paper
Yaohui Wang and Antitza Dantcheva
In Proc. FG, Buenos Aires, Argentina, 2020.
Paper
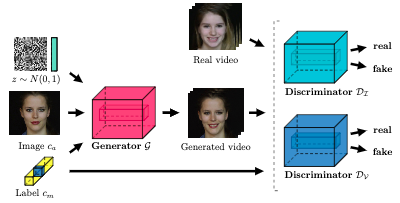
From attribute-labels to faces: face generation using a conditional generative adversarial network
Yaohui Wang, Antitza Dantcheva and Francois Bremond
In Proc. ECCV Workshop, Munich, Germany, 2018.
Paper
Yaohui Wang, Antitza Dantcheva and Francois Bremond
In Proc. ECCV Workshop, Munich, Germany, 2018.
Paper
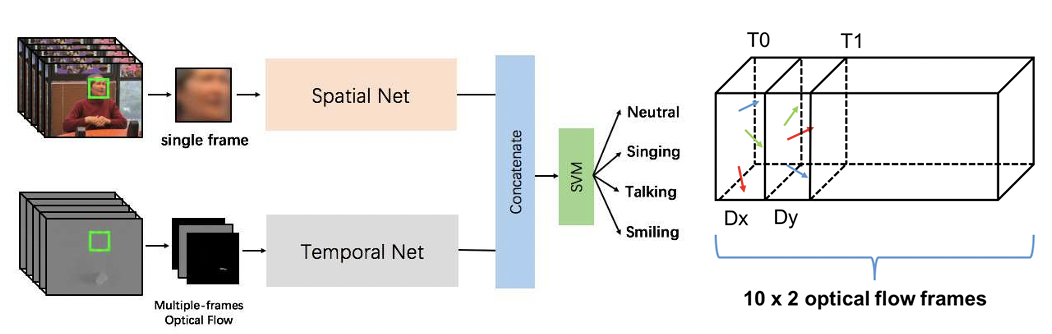
Comparing methods for assessment of facial dynamics in patients with major neurocognitive disorders
Yaohui Wang, Antitza Dantcheva, Francois Bremond and Piotr Bilinski
In Proc. ECCV Workshop, Munich, Germany, 2018.
Paper
Yaohui Wang, Antitza Dantcheva, Francois Bremond and Piotr Bilinski
In Proc. ECCV Workshop, Munich, Germany, 2018.
Paper
Professional activities
Reviewer
SIGGRAPH 2022, CVPR 2022/2021, ECCV 2022/2020, WACV 2020 ...
PhD Thesis

Learning to Generate Human Videos
Yaohui Wang
Thesis
Defense Jury:
Yaohui Wang
Thesis
Defense Jury:
- George Drettakis (President), Inria Sophia Antipolis, France
- Ivan Laptev, Inria Paris/École normale supérieure, France
- Elisa Ricci, University of Trento, Italy
- Shiguang Shan, Chinese Academy of Sciences, China
- Sergey Tulyakov, Snap Research, USA
- Panayiotis Georgiou, Apple Inc./University of Southern California, USA
Teaching
Winter 2021
Deep Learning for Computer Vision, Lecture and TA, MSc of Data Science and Artificial Intelligence, 3IA Cote d'Azur
Winter 2020
Deep Learning for Computer Vision, Lecture and TA, MSc of Data Science and Artificial Intelligence, 3IA Cote d"Azur